SpamClassifier
A website to visualize why emails are spam.
Introduction
This project draws its inspiration from the SpamAssassin database, which is a corpus of 1,897 spam and 4,150 normal emails with labels. I wanted to build a classifier that could identify spam emails, visualize the words that trigger the classifier, and create a searchable interface to see the dataset annotated with these keywords.
Model
The machine learning model contains a pipeline that transforms each email into data that can be input into a machine learning classifier. An email consists of several header fields that contain metadata such as the sender, receiver, and subject followed by the email’s content. My pipeline focuses only on the fields that contain prose text: the subject and body. I used the mailparser library to extract these fields from the emails.
These fields may contain irregular elements that need to be processed in a special way to obtain useful information from them. For instance, some emails contained HTML markup in the body: these elements were removed and replaced with plain text using the beautifulsoup library. The other special case were emails contained special characters, such as those from foreign languages: these were handled using ftfy. Finally, for simplicity, the subject and body are merged and processed as a single string.
The next step in the pipeline is tokenization and stemming. The former breaks a string into its individual building blocks (ie. words). Although this may seem like a simple step, the peculiarities of natural language, including as non-standard punctuation, contractions, and compound words, make this a non-trivial task. After evaluating several tokenizers, I found that the TweetTokenizer in the nltk package produced qualitatively the best results. After this step comes stemming, which reduces each token to its root if one exists. For example, the words “derive”, “deriving”, and “derived” all stem to the same root “deriv” when using the SnowballStemmer. Since all these words are analogous, the stemmer reduces them to a common stem, which allows for all these to be treated as one variable. At the end of all these steps, an email is transformed into a sequence of stem words.
Finally, this sequence is input into the TF-IDF vectorizer in scikit-learn, which converts the stem words into a vectorized model ready to use in a classifier. Namely, it determines which 5000 words occur most frequently, and encodes each as a separate variable. Each variable’s value is the word frequency in the email weighted by the inverse of its frequency in all the documents: if a word appears frequently in an email but is less common in other emails, it will be weighted higher.
I chose a linear model in XGBoost as the classifier because its coefficients can be directly interpreted. I used a grid search with 5-fold cross validation to determine the best regularization parameters, considering both L1 and L2 terms. The best model did not use any regularization.
Website
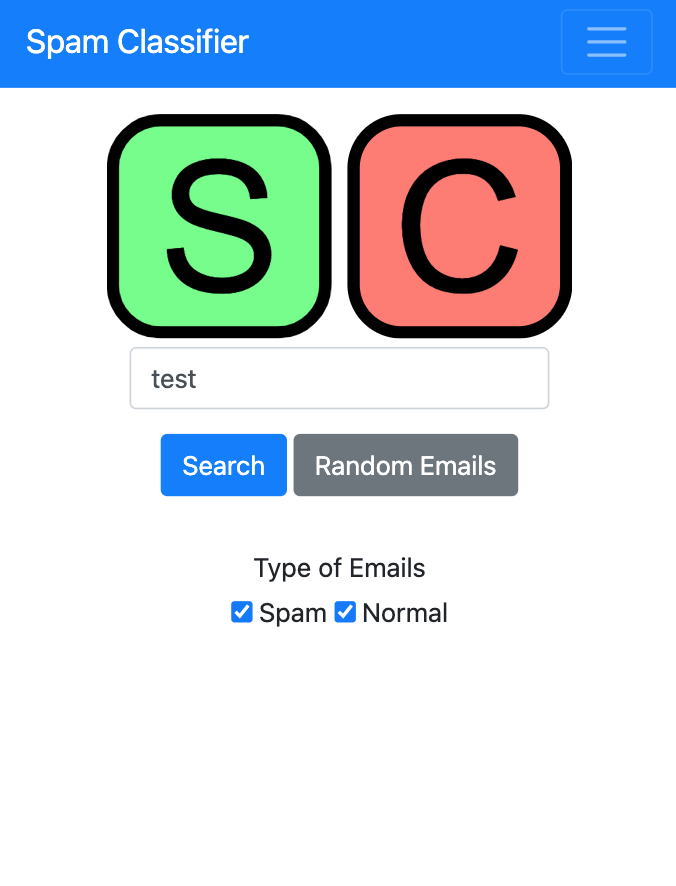
The SpamClassifier website contained a searchable database of keywords and emails. For the frontend, I used a combination of Bootstrap, d3, and jQuery. The backend relies on sqlite to store the emails and model information as well as flask handle requests and serve content. The searching functionality of the website is done through the sqlite full text search utility. All the code and the database is combined into a single Docker image and deployed on AWS with Elastic Beanstalk.
Results
The classifier has a 98.9% accuracy when tested on 20% of the dataset (only 80% of the dataset was used during training). When using 5-fold cross-validation on the training set, the classifier had an out-of-fold average accuracy of 98.1%. This is a significant improvement over 74% accuracy achieved for a classifier that naively categorizes all emails as normal. Below is a wordcloud of some of some of the most significant words in the classifier.

The words that are red are more likely to be associated with spam emails, while green words indicate that an email is normal. The size of the word corresponds to how frequently it appears within emails from the dataset.
In conclusion, this project is an end-to-end machine learning project to classify emails as spam or normal. I found that a simple linear classifier provided good accuracy while also having parameters that can be interpreted. I visualized these results and created a searchable web interface for the dataset and the model’s paramters. This can help users understand which words can trigger a model spam classifier.